소개
- 2019년 구글 딥마인드 팀에서 알파스타를 발표했다.
- 바둑에서의 알파고처럼 스타크래프트2를 하는 인공지능이다.
- 여기서 사용된 인공지능 알고리즘이 강화학습이다.

- 인공지능이 하는 스타2
- 일점사를 배웠다
강화학습이란?
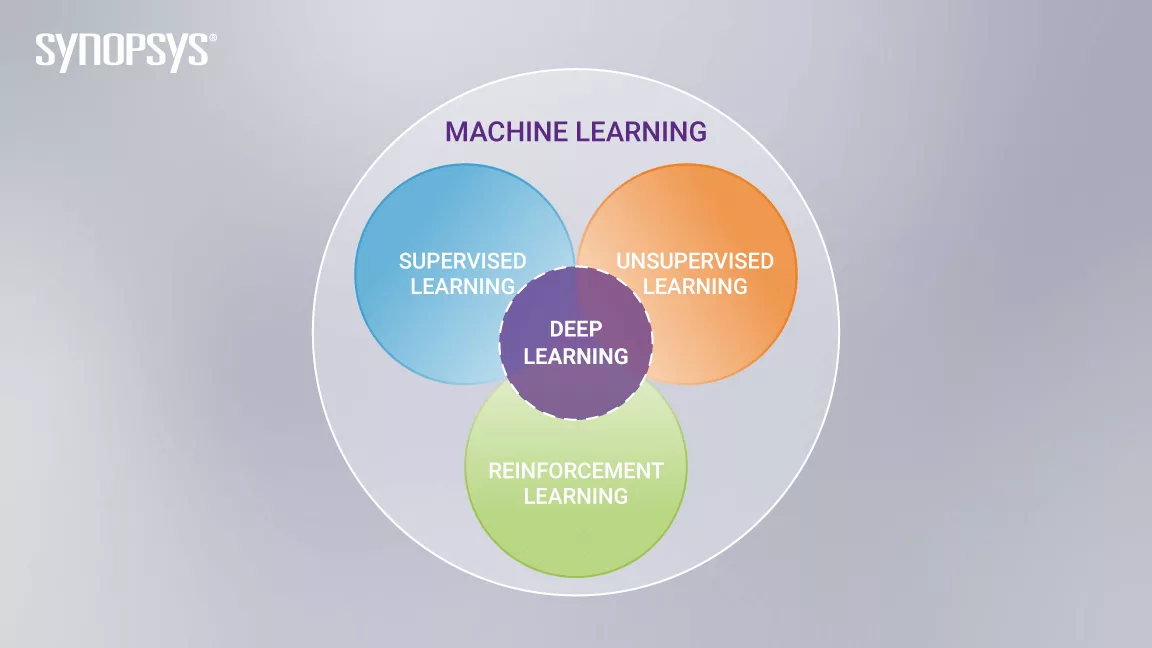
- 강화학습은 기계학습의 한 영역이다.
- 지도학습과 비지도학습과는 다르다.
- 어떤 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법
- (참고) 교육심리학에서 비슷한 이론이 있다. 행동주의 심리학 중에 보상을 제공해서 행동에 대한 반응을 강력하게 하는 방법론이다. 다시 말해 잘하면 상을 주는 방법이다.
용어 설명
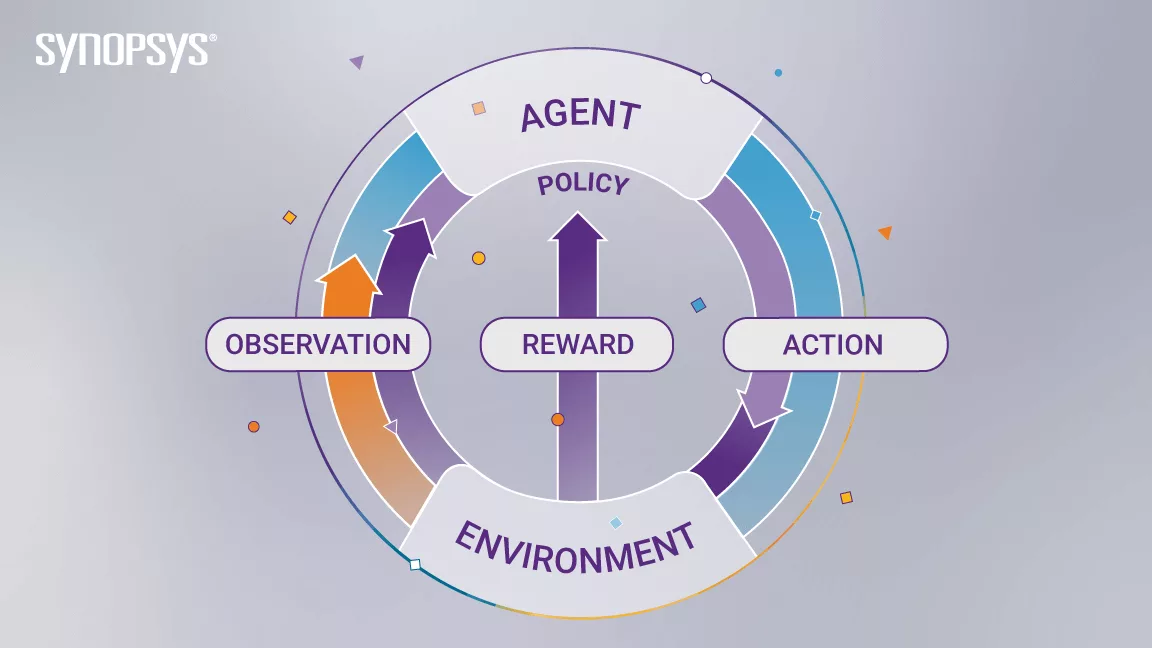
- agent : 의사결정의 주체, 함수를 통해 다음 행동을 결정함 . 두뇌
- envirinment : 에이전트가 학습하는 무대. 환경은 agent의 state와 reward를 결정함. agent에게 공개되어 있지 않은 경우가 많음
- observation: agent가 환경으로부터 받는 정보
- action(a) : 가능한 행동을 선택함
- reward : agent 가 특정 action을 했을 때 받는 신호. 즉각적 보상이 안이루어지는 경우도 있음
- policy: agent의 행동패턴. 환경을 행동에 연결짓는 함. a = π(s)
- optimal policy: 강화학습의 목적은 optimal policy를 찾는 것
- return(G): 보상. agent가 time에 따라 받게될 할인된 보상의 누적
- ε - greedy :
- Q - learning : 모델 없이 강화하는 학습 방법 중 하나. 주어진 상태(s)에서 주어진 행동(a)를 수행하는 것이 가져다 줄 효용의 기대값을 예측하는 함수인 Q함수를 학습함으로써 최적의 정책을 학습함
반응형